Aapo Puhakka
26.4.2001
http://aapo.iki.fi
Tässä artikkelissa kerrotaan laaja-alaisesti käytännöistä ja mahdollisuuksista kehitää vikasietoisia ja virheitä välttäviä ratkaisuja tämänpäivän ja lähitulevaisuuden tietotekniikassa. Artikkeli perustuu Ravishankar K. Iyer:in artikkeliin kirjassa `HAL's Legacy'. Muita lähteitä käytetään alueilla, jotka eivät kuulu alkuperäiseen artikkeliin, erityisesti toteutustason ohjelmoinnissa, formaaleissa menetelmissä ja eräissä uusissa ohjelmistotuotannon mahdollisuuksissa.
This paper discusses practices and possibilities in fault tolerance and fault avoidance today and in near future in wide sense. Paper is based on Ravishankar K. Iyer's article in book 'HAL's Legacy'. Other references are used in areas which the original article doesn't cover. Particularly aspects in implementation-level programming, formal methods and new ideas about software engineering processes.
Luotettavan tietotekniikan rakentaminen on hyvin laaja aihe ja siinä voidaan käyttää monia erilaisia menetelmiä. Mielestäni alkuperäisessä artikkelissa ei ole käsitelty tiettyjä oleellisia käytännöllisiä seikkoja ja uusia mahdollisuuksia ja lähinnä niistä olen kerännyt uusia lähteitä.
Luotettavan tietotekniikan rakennusmenetelmät voidaan jakaa kahteen osaan: vikasietoisuuteen ('fault tolerance') ja virheiden totaaliseen välttämiseen ('fault avoidance') ( Iyer, 1995 ) . Lukujen 2-4 menettelytavoilla pyritään saavuttamaan järjestelmä, joka kykenee toimimaan vioista huolimatta. Lukujen 5-8 menetelmillä pyritään pääsemään vioista kokonaan eroon.
Periaatteessa voidaan määritellä, että järjestelmässä on virhe, jos järjestelmän toiminta ei vastaa dokumentaatiota ( Haikala ja Merijärvi, 1997 ) . Erilaiset viat voidaan yleisesti tekniikassa jakaa suunnitteluvirheisiin, valmistusvirheisiin, fyysisistä olosuhteista aiheutuneisiin virheisiin ja dokumentaatiovirheisiin. Laitteistoviat ovat pääosin fyysisistä olosuhteista aiheutuneita, vaikka myös muuntyyppisiä virheitä voi olla. Ohjelmistovirheet ovat lähes ainoastaan suunnitteluvirheitä tai dokumentaation virheitä.
Kirjallisuudessa saatetaan erotella ohjelmistovirheitä suunnittelu- ja toteutusvirheisiin, mutta nämä molemmat ovat saman tyyppisiä virheitä kuin laitteistojen suunnitteluvirheet. Fyysisistä olosuhteista, kuten kulumisesta, aiheutuneet virheet saattavat ilmestyä tuotteeseen yhtäkkiä. Sen sijaan suunnitteluvirheet eivät ilmesty, ne ovat tuotteessa koko ajan.
Myös ohjelmistoissa saattaa ilmetä yhtäkkisiä vikoja ilman laitteistohäiriöitä. Tällöin järjestelmä on joutunut johonkin epästabiiliin tilaan; käytännössä joissakin järjestelmän muistipaikoissa on arvoyhdistelmä, jota järjestelmän suunnittelijan mielestä ei ollut mahdollista saavuttaa. Mutta myös tämänkaltaiset ongelmat on katsottava suunnitteluvirheiksi.
Iyer ( 1995 ) mainitsee erikseen laitteisto- ja ohjelmistovirheiden lisäksi omana ryhmänään käyttöliittymävirheet sen tarkemmin niitä käsittelemättä. Toisaalta jos käyttöliittymän toiminta ei vastaa dokumentaatiota, niin kyseessä on perinteinen ohjelmistovirhe. Sen sijaan käyttöliittymävirheen voisi määritellä esimerkiksi seuraavasti: ''Merkittävä osuus järjestelmän käyttäjistä ei suoriudu tietystä toimenpiteestä halutussa ajassa.'' Kuitenkin parempana käsitteenä voitaisiin pitää käytettävyysvirhettä tai -ongelmaa, sillä ongelman syy voi olla jossain muuallakin kuin käyttöliittymässä -- kuten ohjeistuksessa tai koulutuksessa.
Perinteisesti luetettavuusasioihin on kiinnitetty huomiota järjestelmissä, joissa yksikin virhe saattaa johtaa ihmishenkien menetyksiin, kuten ilmailu- ja avaruusalan sovelluksissa. Viime aikoina luotettavuutta takaavia menetelmiä on alettu yhä enemmän käyttää tavallisemmissa kaupallisissa kohteissa, kuten yritysten toiminnan kannalta keskeisissä järjestelmissä. ( Iyer, 1995 )
Usein luotettavuuden lisääminen järjestelmään hidastaa järjestelmän toimintaa. Esim. tietokannat toimisivat nopeammin ilman transaktioita, redundantin informaation ylläpitäminen vaatii ylimääräistä työtä, kuittausten odottelu tietoliikenteessa hidastaa toimintaa.
Laitteistovirheet aiheutuvat useimmiten fyysisistä olosuhteista, esim. normaalista kulumisesta. Tämäntyyppisiä virheitä vastaan suojaudutaan lisäämällä ns. redundanssia, eli toistetaan muutoin tarpeettomasti laitteistoja tai informaatiota.
Toistettaessa laitteistoa (esim. avaruusaluksissa, lentokoneissa), meillä on järjestelmä, jossa on useampia tietokoneita, jotka suorittavat samaa ohjelmistoa. Kaikki laskennan tulokset alistetaan äänestysjärjestelmälle, joka päättää laskennan tulokseksi sen, johon enemmistö koneista päätyi. Myös äänestyskäsittelijöitä voi olla useampia, jos epäillään, että sellainen saattaisi hajota.
Informaatiota voidaan toistaa matalalla tasolla esim. pariteettibiteillä (8-bitin sarjaa kohden on ylimääräinen bitti, joka kertoo, onko ykkösiä pariton vai parillinen määrä) tai Hamming-koodilla (jossa on kolme ylimääräistä bittiä ja yhden bitin virheet on mahdollista korjata ja kahden löytää ( Halshall, 1995 ) ( Mano, 1988 ) . Uudempi menetelmä on ns. ECC -koodi (Error Correction Code), joka pystyy korjaamaan 3 bittiä 32:sta ja havaitsemaan neljän bitin virheen ( Rein, 2001 ) . Näitä koodeja käytetään erityisesti RAM-muisteissa. Muistivirheitä on mahdollisuus hallita myös dynaamisesti ohjelmistolla ( Rein, 2001 ) .
Tietoliikenteessä käytetään näiden lisäksi hieman pitemmästä datamäärästä laskettuja CRC (Cyclic Redundancy Check) -koodeja ( Halshall, 1995 ) . On olemassa useita kehittyneitä pakettipohjaisia protokollia (kuten TCP/IP), jotka kykenevät takaamaan pakettien perillepääsyn epäluotettavan kanavan yli kuittausten avulla ( Comer, 1995 ) .
Massamuisteissa on erilaisia RAID (Redundant Array of Inexpansive Disks) -ratkaisuja käytössä. Niissä on ideana, että sama data on talletettu useammalla fyysiselle levylle, mutta se esitellään ohjelmille yhtenä levynä. Jos yksittäinen kovalevy hajoaa, niin informaatiota ei menetetä, eikä toimintaa tarvitse keskeyttää. RAID ratkaisujen heikkoutena on RAID-kontrolleri: jos se hajoaa, niin koko järjestelmä saattaa olla menetetty.
Tietokannoissa voidaan redundanttia informaatiota hyödyntää ilman \\ RAID:ia käyttämällä ns. replikoivaa kantaa, joissa useampaan tietokantaan, joilla ei ole yhteistä fyysistä tallennusvälinettä, talletetaan sama informaatio. ( Dove, 2001 )
Iyer ( 1995 ) esittää myös mahdollisuuden ns. aikaredundanssiin `time redundancy', eli toistetaan sama laskentaoperaatio useamman kerran peräkkäin. Käytännössä tämä ei ole kovin hyödyllinen toimintatapa, koska aikaredundanssilla ei kuitenkaan voida toipua kuin satunnaisista (esim. kosmisen säteilyn) aiheuttamista virheistä ja satunnaiset häiriöt voidaan ratkaista usein myös redundantilla informaatiolla. Erikoistapauksissa menetelmä saattaa kuitenkin olla hyödyllinen.
Ohjelmistovirheitä vastaan ei voida suojautua vain käyttämällä rinnakkain samaa ohjelmistoa useammassa eri koneessa, koska ohjelmistovirheet ovat pääosin suunnitteluvirheitä. Jos toinen samaa ohjelmistoa käyttävä tietokone jumittuu, niin myös toinen jumittuu. Tämänkaltainen ratkaisu oli osasyynä Ariane 5 -raketin räjähdykseen kesäkuussa 1996 ( Lions et al, 1996 ) .
Sitä vastoin, jos meillä on useita eri toteutuksia samasta rajapinnasta, niin vastaavanlaisia toisto-äänestys -ratkaisuja voidaan tehdä ( Iyer, 1995 ) . Toisaalta voidaan kritisoida, että jos meillä on käytettävissä rajoitettu määrä resursseja johonkin projektiin, niin onko järkevää käyttää resursseja erillisten toteutuksien tekemiseen samasta asiasta, vai kannattaako mieluummin käyttää resurssit yhteen mahdollisimman hyvään toteutukseen.
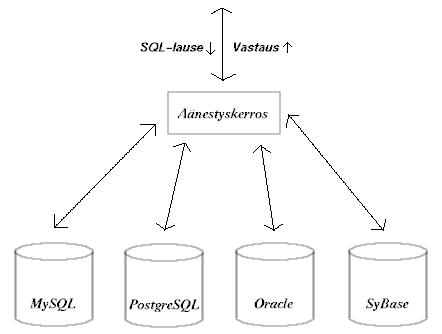
Toisaalta, jos ao. moduulista on jo olemassa useita kilpailevia ratkaisuja, niin voidaan tehdä esim. kuvan 1 mukainen ratkaisu.
Kuva 1: Jos haluamme suojautua hyvin vioilta tietokantojen toteutuksessa, voimme rakentaa arkkitehtuurin, jossa jokainen SQL-lause välitetään kilpaileville tietokannoille ja oikea vastaus hakulauseissa valitaan äänestyksen perusteella. Jos joku tietokanta antaa poikkevan vastauksen, esim. tietokantapalvelin voidaan määrätä uudelleen käynnistettäväksi tai koko tietokanta uudelleen perustettavaksi.
Suunniteltaessa algoritmeja on oleellista pyrkiä siihen, että mahdollisesti syntyvät virheet pyrkivät konvergoitumaan (häviämään) eikä divergoitumaan (kasvamaan). Jos esimerkiksi joidenkin olioiden lukumäärästä halutaan pitää tietoa summamuuttujassa, niin divergoiva tapa toimia on joka kerta lukumäärän muuttuessa vain suoraan kasvattaa tai vähentää ao. muuttujaa. Kuitenkin, jos jossain tilanteessa muutoksen määrä on päätelty väärin, niin muuttujaan tulee virhe, joka ei katoa myöhempien operaatioiden seurauksena. Sen sijaan, jos muutettaessa lukumäärämuuttujaa joka kerta lasketaan itse oliot yksitellen, mahdollinen virhekäsitys muutoksen määrästä ei vaikuta summamuuttujaan.
Tiettyjen operaatioiden määritteleminen atomäärisiksi lisää luotettavuutta erityisesti monen käyttäjän (monen säikeen) järjestelmissä. Atomäärinen operaatio tarkoittaa, että jos joku (käyttäjä tai säie) on aloittanut jonkun atomäärisen operaation, kukaan muu ei pysty suorittamaan sitä samaan aikaan ja mahdollisesti sotkemaan tilannetta ( Iyer, 1995 ) .
Tietokannoissa atomäärisistä operaatioista käytetään nimitystä transaktio. Lisäksi transaktiot on mahdollista hyväksyä tai perua. Eli, jos toteamme jossain transaktion keskellä virhetilanteen, niin perumme koko operaation, ja tällöin mikään operaatiossa käsitelty tieto ei jää virheelliseen välitilaan. Tilanteissa, joissa transaktio joudutaan perumaan, voidaan käynnistää myös erilaisia tietorakenteiden virheiden etsintä- ja korjausmenetelmiä.
Virheitä on mahdollista välttää ohjelmoinnissa pyrkimällä jatkuvasti tiettyyn yksinkertaisuuteen, jos joku metodi kasvaa hiemankin pitemmäksi, se on jaettava useampaan osaan, jotta se säilyy selkeänä. Mitä monimutkaisempi metodi on, sitä suurempi on mahdollisuus, että sinne voi piiloutua erilaisia virheitä tai heikkouksia tarkistavilta katseilta.
Koodia pitää jatkuvasti tarkkailla, ettei siinä toteuteta samaa asiaa useampaan kertaan. Jos sama asia toteutetaan erillisesti kahdessa eri funktiossa se on syytä muotoilla uudestaan siten, että tämä asia voidaan toteuttaa jossain yleiskäyttöisessä funktiossa. Yleiskäyttöisistä funktioista on se etu, että kun joku asia on saatu jo kerran toimimaan, siitä ei tarvitse tehdä uusia toteutuksia, joissa mahdollisesti tehdään uudestaan jo aikaisemmin korjattuja virheitä. Samoin, jos havaitaan jokin virhe yleiskäyttöisessä funktiossa, niin virhe saadaan korjattua tekemällä muutokset yhteen ainoaan paikkaan. Muutoin koodia pitäisi korjata monesta eri kohdasta, jolloin joku kohta jää todennäköisesti huomaamatta.
Keskeytysten käyttäminen on erinomainen käytäntö virheiden välttämisessä. Jokaisen metodin alussa on syytä tarkistaa, että metodin parametrien ja metodin käyttämien luokan sisäisten muuttujien arvot ovat oletetuissa rajoissa. Jos jonkin muuttujan tai parametrin arvo on odottamaton on aiheutettava keskeytys. Keskeytykset on jaettava eri luokkiin sen mukaan, voiko virhe olla seurausta esim. käyttäjän virheellisestä syötteestä vai onko virheen syynä todennäköisesti joku ohjelmistovirhe jossain muualla.
Ajatus, että voitaisiin matemaattisesti todistaa pelkän ohjelmakoodin perusteella ohjelman toimivan oikein, on kiehtova ja mielestäni kuuluu yleiseen luotettavaa tietotekniikkaa käsittelevään artikkeliin, vaikkakin formaalien menetelmien soveltamista käytännössä on pidetty erittäin vaikeana ja kannattamattomana ( Begay ja Rauzy, 2001 ) .
Periaatteessa on todistettu, että mikään Turingin kone ei pysty ratkaisemaan kysymystä, onko toinen Turingin kone jäänyt ikuiseen silmukkaan. Eli kysymys siitä, voiko mikä tahansa annettu ohjelma jäädä ikuiseen silmukkaan on ratkaisematon ( Lewis ja Papadimitrou, 1981 ) . Toisaalta ei ole tarpeen todistaa minkä tahansa ohjelman toimivuutta. Jos ohjelma on jaettu riittävän yksinkertaisiin osiin kohdan 5 mukaisesti, voisi luulla yksittäisten metodien virheettämän toiminnan todistamisen olevan mahdollista. Sitä kautta myös koko järjestelmän.
Formaalien menetelmien heikkoutena on myös, että jos virhe määritellään, että ''toiminta ei vastaa dokumentaatiota'', eivät formaalit menetelmät ole käyttökelpoisia, koska ne eivät kykene käsittelemään ihmisten luettavaksi tarkoitettua dokumentaatiota. Toisaalta ohjelman jokaisessa metodissa voidaan pyrkiä aiheuttamaan tietty keskeytys, jos jonkun muuttujan arvo on sellainen, jota ei voida saavuttaa muutoin kuin ohjelmavirheen seurauksena. Tällöin formaaleja menetelmiä voidaan käyttää kysymyksen ''Onko mahdollista, että tässä järjestelmässä ilmaantuu tämän tyyppinen keskeytys?'' -selvittämiseen.
Tosin tämänkaltaisia keskeytystyyppejä hyväksikäyttäviä todistuksia ei ole juurikaan vielä tehty. Mutta sen verran voidaan todeta, että väite todellisen lentotekniikassa käytetyn ohjelman (C-koodia) virheettömyydestä on kyetty kumoamaan formaaleilla menetelmillä ( Begay ja Rauzy, 2001 ) .
Rinnakkaisissa järjestelmissä ongelmana saattaa olla, että vaikka järjestelmän mikään osa ei olisi jäänyt pysyvästi jumiin, niin jonkun vähemmän kriittisen operaation suoritus viivästyy tai estyy, koska muita kriittisempiä palvelupyyntöjä saapuu tasaisena virtana. Eli järjestelmä ei toimi ''reilusti'' joitain operaatiota kohtaan. Tämänkaltaisia ongelmia kuvaavia kriteereitä kutsutaan reiluusehdoiksi. Viime aikoina formaaleilla menetelmillä on tutkittu paljon reiluusehtoja, esim. erilaisten alternating-bit -tyyppisten protokollien toimivuus on kyetty todistamaan voimakkaillakin reiluusehdoilla ( Puhakka ja Valmari, 2000 ) .
Jotta voisimme tuottaa mahdollisimman tasalaatuisia tuotteita, tarvitaan yleensä jonkinlainen laatujärjestelmä toiminnan kontrollointiin. Myös ohjelmistotuotannossa laatujärjestelmä tuo tasalaatuisuutta.
Perinteisesti testaus on nähty vaiheena, jossa pyritään poistamaan virheitä ja saavuttamaan luotettavuutta. Testaus pyritään suorittamaan V-mallin mukaisesti määrittely- tai suunnitteludokumentteja vastaan. Tällöin moduulisuunnittelua vastaa moduulitestaus ja arkkitehtuurisuunnittelua integrointitestaus. ( Haikala ja Merijärvi, 1997 ) Testaaja ei saisi olla sama henkilö, joka on ohjelmoinnin suorittanut, koska ohjelmoija herkästi on sokea ratkaisuilleen, eikä tule ajatelleeksi toimintavaihtoehtoja, joissa ratkaisu ei toimi.
Testauksella ei kuitenkaan kyetä takaamaan järjestelmän virheettömyyttä, koska kaikkia ohjelman suorituspolkuja ei ole mahdollista käydä läpi. Testausta lisäämällä voidaan kuitenkin pienentää virheiden esiintymisen todennäköisyyttä.
Viime aikoina on esitetty ajatus, että ennen varsinaista tietyn moduulin toteuttamista tulisi kirjoittaa moduulin toiminnan testaava koodi. Samoin, jos havaitaan virhe, niin ensimmäisenä tulee toteuttaa testikoodi, jolla virhe saadaan esiin. ( Beck, 1999 ) Tästä on se etu, että projektin edetessä kasvaa testauskoodivarasto, jonka läpi voidaan jokainen uusi versio ajaa ja siten varmistaa, ettei samoja virheitä pääse esiintymään uudelleen.
Virheiden löytäminen tarkastelemalla moduulia pelkkänä mustana laatikkona, jonka sisälle ei katsota, tuntuu epäoptimaaliselta tavalta havaita virheitä. Siksi olisikin suotavaa testauksen lisäksi suorittaa kooditarkastuksia, joissa esim. kokeneempi ohjelmoija tarkastaa koodin jokaisen kohdan siten, että ymmärtää sen eikä hyväksy koodia, jos joku kohta joko ei noudata sovittuja laatukäytäntöjä, voitaisiin toteuttaa paremmin, sisältää piilevän virhemahdollisuuden, on vaikealukuinen tai toteuttaa uudestaan joitain asioita, jotka on jo toteutettu muualla. Toisena vaihtoehtona on koodin läpikäynti siten, että ohjelmoija tekee kolleegoilleen ''esittelykierroksen'' kohteena oleviin dokumentteihin. On väitetty, että tällöin ohjelman tekijä löytää itse n. 80\% ongelmakohdista ( Colen, 2001 ) .
Aivan viime aikoina on perustellusti -- joskin kiistanalaisesti -- esitetty, että julkisen lähdekoodin menetelmillä saadaan aikaan luotettavampia ohjelmistoja kuin käytännöillä, joissa lähdekoodi on suuri salaisuus.
Perustelut, miksi julkinen lähdekoodi tuottaa luotettavia ratkaisuja, ovat pitkälti samankaltaisia, kuin miksi tieteellinen menetelmä tuottaa luotettavia ratkaisuja. Tieteellisessä menetelmässä julkistetaan kaikki tehdyt kokeet ja todistukset laajan tiedeyhteisön tarkastettavaksi. Jos tehdyssä todistuksessa on virhe tai koetta ei pystytä toistamaan, niin tästä seuraa palautetta ja päätelmää ei hyväksytä. ( DiBona, 1999 )
Jos koodissa on joku virhe tai heikkous, se tulee joka tapauksessa jossain vaiheessa esille ja ongelma on mahdollista korjata, jopa toisessa maassa asuvan henkilön toimesta. Jos koodi on salaista niin yritys, joka omistaa ao. koodin voi yrittää työntää markkinoille tuotetta, jossa on pahoja luotettavuusongelmia. Jos lähdekoodi on julkista, niin mahdollisten kooditarkastajien joukko on paljon suurempi, kuin suurimmallakaan suljetun koodin yrityksellä voi olla. ( DiBona, 1999 ) ( Vixie, 1999 )
Menestyneissä julkisen lähdekoodin projekteissa ohjelmistonkehitysprosessina on ns. ''basaarimenetelmä''. Tässä projektilla on yksi yhdistämisen suorittava vastuuhenkilö (integroija) ja mahdollisesti satoja testaajia, debuggaajia, yksittäisten ongelmien ratkaisijoita ja parannusehdotusten lähettäjiä ympäri maailmaa. Tämän hajautetun porukan toimintaa ei kontrolloida juuri millään lailla. Päällekkäistä työtä estetään lähinnä julkaisemalla usein (vähintään kerran viikossa, joskus jopa useasti päivässä) uusia versioita projektista. Lisäksi löydetyt virheet saatetaan rekisteröidä yhteiseen paikkaan. Projektiin osallistuvien motiivina on jokin henkilökohtainen syy; esim. kehitettävä ohjelma saattaa ratkaista jonkin henkilökohtaisen konkreettisen ongelman. Tavallaan ohjelmoijat ja testaajat ovat itse asiakkaan roolissa. ( Raymond, 1999 )
Voidaan myös perustellusti kritisoida, ettei tällainen basaarimenetelmä voi toimia kaikissa ohjelmistoprojekteissa. Erityisesti, jos kehitettävä ohjelma ei ratkaise tarpeeksi suuren ja ohjelmointia harrastavan käyttäjäjoukon ongelmia. Esimerkiksi tällaisia ovat räätälöidyt ja sulautetut järjestelmät. Mutta toisaalta voi olla, että useimpien ''vähän tarvittujen'' ongelmien ratkaisu auttaisikin ympäri maailmaa olevaa satojen ihmisten joukkoa, joka voisi olla kiinnostunut kuluttamaan hieman aikaansa ongelman ratkaisemiseksi.
On esitetty myös, ettei tällainen julkisen lähdekoodin kehitystapa ole taloudellisesti mahdollinen, ohjelmoijat eivät saa palkkaansa. Toisaalta myös ideoidaan ja kokeillaan liiketoimintamalleja, joilla ammattimainen toiminta olisi mahdollista ( Tiemann, 1999 ) ( Young, 1999 ) ( Behlendorf, 1999 ) .
Lisäksi, jos julkisen lähdekoodin kehitystä ei voida rahoittaa tavanomaisin taloudellisein keinoin, voidaan kysyä, pitäisikö valtion tai yliopistojen rahoittaa tämänkaltaista toimintaa.
Tietojärjestelmien virheiden välttäminen ja sietäminen ovat monimutkaisia ongelmia, joihin on olemassa monenlaisia ratkaisumahdollisuuksia. Tänä päivänä laitteistovirheet ovat paljon tutkittu ala, johon on jo saatavilla hyvin toimivia ratkaisuja. Uusia vaihtoehtoja laitteisto-ongelmien ratkaisemiseksi todennäköisesti vielä ilmaantuu.
Ohjelmistovirheet ovat tällä hetkellä huomattavasti hankalammin hallittavia, mutta mielenkiintoisia mahdollisuuksia on nähtävissä. Erityisesti mahdollisuuksia on virheiden välttämisen alalla mm. toteutustekniikoiden soveltamisessa, formaaleissa menetelmissä ja uusissa ideoissa ohjelmistonkehitysprosesseista. Mielestäni ohjelmistovirheiden hallinta on tällä hetkellä vielä sen verran alkutekijöissään oleva ala, että pitäisin jopa todennäköisenä, että uusia, mullistaviakin lähestymistapoja ohjelmistovirheiden hallitsemiseksi tulee ilmaantumaan.